|
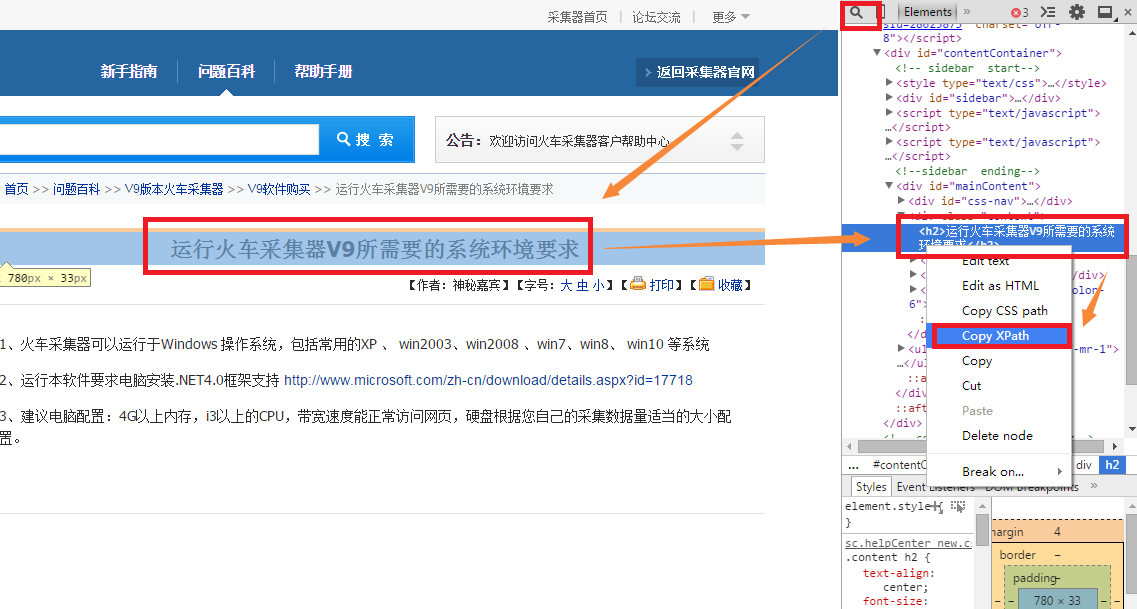
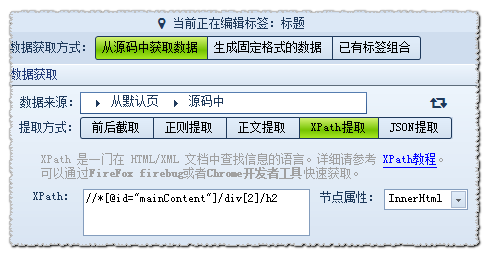
我们在使用抓取网页数据工具火车采集器时,经常会用到不同的数据提取方式,除了前后截取、正文提取、正则提取之外,Xpath提取也是常用的一种。XPath是一门在 HTML/XML 文档中查找信息的语言,XPath使用路径表达式在XML文档中进行导航,可以通过FireFox firebug 或者Chrome 开发者工具快速获取。下面就详细地演示下抓取网页数据工具火车采集器的Xpath提取示例。 XPath节点属性 innerHTML:获取位于对象起始和结束标签内的 HTML (HTML代码,不包含开始/结束代码) innerText:获取位于对象起始和结束标签内的文本 (文本字段,不包含开始/结束代码) outerHTML:获取对象及其内容的HTML形式 (HTML代码,包含开始/结束代码) Href:获取超链接 以网址http://faq.locoy.com/q-682.html为例,我们来设置标题和内容的XPath表达式,这里的节点属性我们默认为innerHTML就可以了,以下是操作步骤的内容。 1、首先,我们用谷歌浏览器打开上面的网页,然后打开Chrome开发者工具,打开开发者工具的快捷键是 “ F12 ”,反复按下F12可以切换状态(打开或关闭)。如果在原网页中,直接右击选择“审查元素”也是可以的。 2、获取标题的XPath,操作如下图: 按照图标箭头的顺序,先点击查找选中标题,右击代码中的选中部分,点击copy xpath,可得出代码为 //*[@id="mainContent"]/div[2]/h2 3、获取内容的XPath,操作如下图: 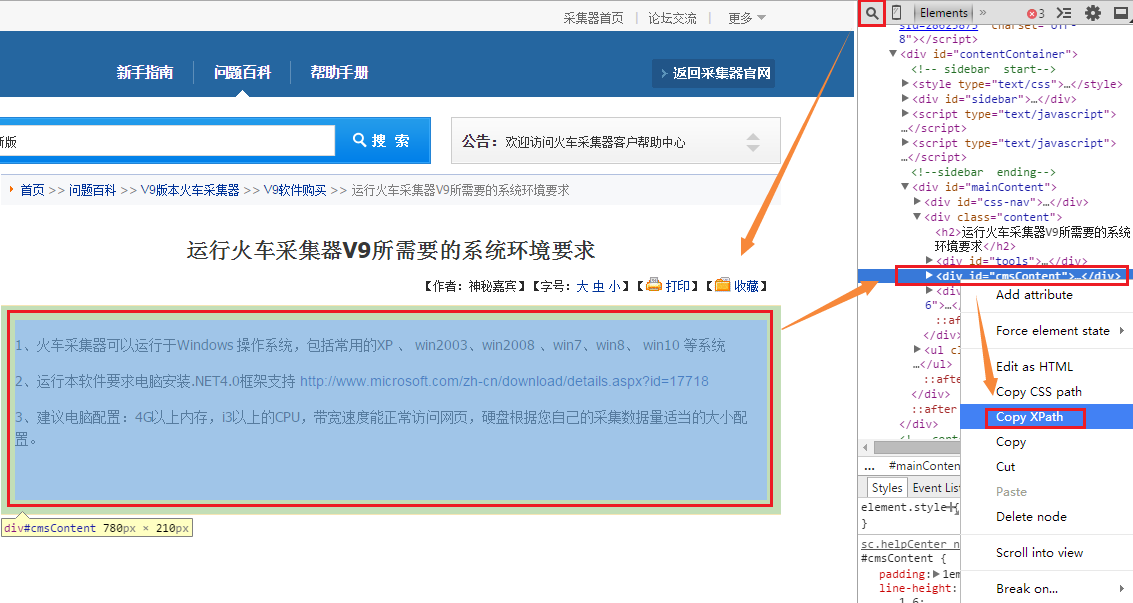 操作和标题操作差不多,但需注意的是,当鼠标悬停在内容上面时,需要选中全部内容而不是部分段落,这样再去代码中点击,才能得出完整的Xpath表达式,右击后复制得出代码为 //*[@id="cmsContent"] 。 看完之后大家有没有觉得Xpath提取很好用,觉得好用的话就自己也来操作试试吧,除了上面提到的四种提取方式外,抓取网页数据的工具火车采集器V9还有JSON提取方式,大家也可以学习研究一下。
|  |手机版|Archiver|火车采集器官方站
( 皖ICP备06000549 )
|手机版|Archiver|火车采集器官方站
( 皖ICP备06000549 )


 发表于 2016-6-7 17:47:44
发表于 2016-6-7 17:47:44