|
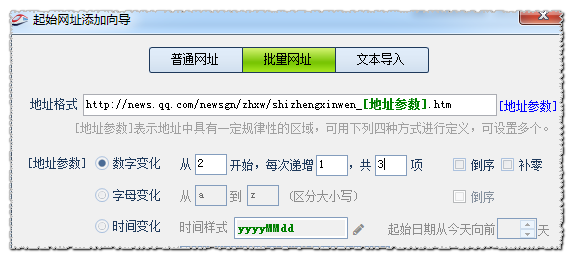
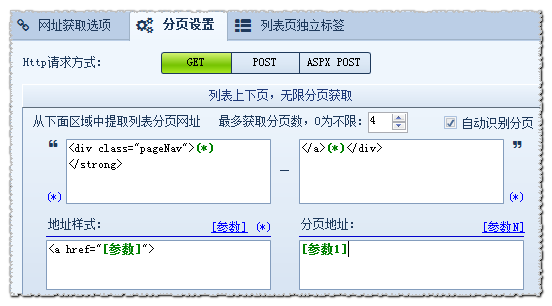
在使用文章采集器采集文章的过程中,我们经常需要对分页进行抓取,比如列表分页或内容分页,这里我们就以列表分页为例,为大家讲解一下火车采集器是如何操作分页的。 对于设置列表分页,通过下图的起始网址——批量网址来设置是最常见也是最常用的。 现在我们用另外一种获取分页的办法,即通过列表上下页无限分页采集获取功能来自动获取分页。使用这个功能,起始页就只需要把首页地址添加进去就可以了,如下图: 
然后进入[高级模式]——分页设置,设置区域开始字符串、区域结束字符串、地址样式、分页地址等字段。 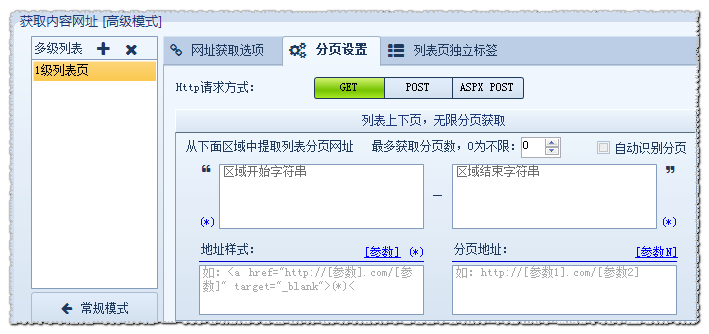
我们以http://news.qq.com/newsgn/zhxw/shizhengxinwen.htm 为例,先查看下第一页分页源代码的情况,如下图:  继续查看下第二页分页源代码的情况如下: 继续查看下第二页分页源代码的情况如下: 分析得出:当前页都是在<div>后的<strong></strong>这个代码后面紧接着一个<a href="">就是下一页地址。 也就是说我们是要通过当前页获取下一页,这样一级一级的向下获取,直至把所有分页获取到。 所以,区域开始字符串为:<div>(*)</strong> 区域结束字符串为:</a>(*)</div> 分析得出:当前页都是在<div>后的<strong></strong>这个代码后面紧接着一个<a href="">就是下一页地址。 也就是说我们是要通过当前页获取下一页,这样一级一级的向下获取,直至把所有分页获取到。 所以,区域开始字符串为:<div>(*)</strong> 区域结束字符串为:</a>(*)</div>

地址样式根据截取区域的格式来写:<a href="[参数]">,效果如下: 另外上图 “4” 是表示获取4页的意思,默认为“0”表示不限,将采集所有分页。这样就可以用火车采集器获取到我们需要的上下页列表分页了,用火车采集器抓取内容页上下页模式也是可以参考这种操作的,更多使用教程可以访问官网进行学习。
|  |手机版|Archiver|火车采集器官方站
( 皖ICP备06000549 )
|手机版|Archiver|火车采集器官方站
( 皖ICP备06000549 )


 发表于 2016-6-23 14:34:13
发表于 2016-6-23 14:34:13